Moltissimi ricercatori, in fase di analisi dei dati, decidono di trasformiate una variabile continua (ad esempio: “pressione arteriosa”, oppure “peso”) in una variabile dicotomica (generalmente con valori “low” e “high”)
Quali motivi li spinge ad una manovra del genere? In generale lo si fa per semplificare l’analisi o per una più facile interpretazione dei dati. Un altro motivo molto “gettonato” è quello per cui la variabile è distribuita in modo molto asimmetrico e si vuole evitare l’effetto che possono avere eventuali outliers sulle stime (in tale caso, però, ti suggerisco altre tecniche più adeguate, come ad esempio la regressione quantilica).
Ma quella di dicotomizzare una variabile è una buona idea?
Dipende.
In generale, tranne che in poche situazioni, la risposta è no.
Perché? Il motivo più evidente è la perdita di informazione contenuta nella variabile continua.
In particolare, se osservi il grafico qua sotto, perdi l’informazione:
in termini “orizzontali” (freccia blu), cioè il range della variabile;
in termini “verticali” (freccia rossa), che rappresenta la variabilità del tuo outcome in relazione al valore della tua variabile continua
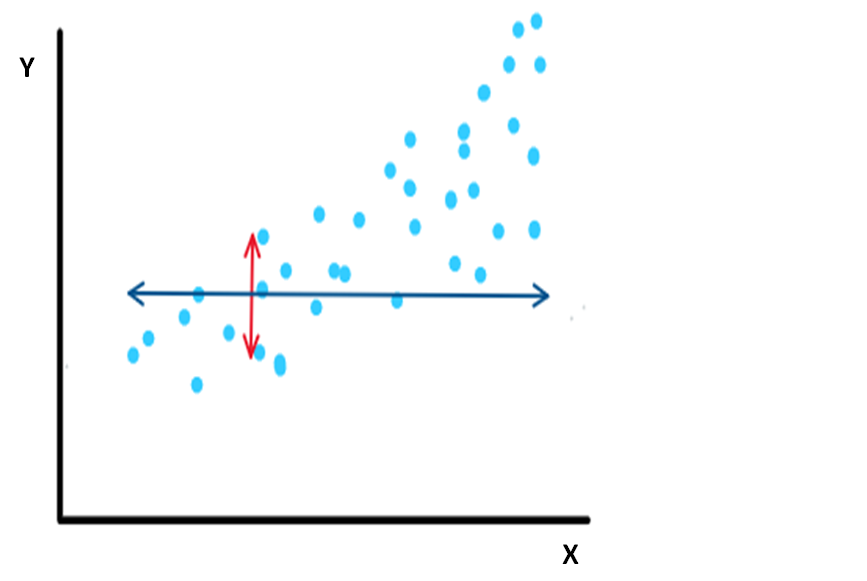
Tu però potresti dire: a me queste informazioni non interessano. Il problema, però, è che rinunciando a queste informazioni viene ridotta anche la potenza della tua analisi. E la riduzione di potenza è considerevole: in linea generale , è equivalente a perdere circa un terzo del tuo sample-size. Se ci pensi è un enormità.
Un ulteriore problema è dato dal “come dicotomizzare la variabile”. Nella maggior parte dei casi viene usata la mediana. Ma la mediana varia da campione a campione e i risultati del tuo studio potrebbero non essere confrontabili con un altro studio in cui la mediana usata per dicotomizzare avrà un valore diverso.
Inoltre c’è un problema più strettamente “logico”: nel momento in cui tu dicotomizzi una variabile stabilendo un cutoff (ad esempio pressione sistolica=120), due valori pressori pratiamente identici, come 119,8 e 120,1, tu li consideri molto diversi, nel momento in cui li fai entrare in due categorie diverse.
Quando, allora, ha senso categorizzare una variabile?
In alcuni casi, tuttavia, dicotomizzare una variabile può avere senso.
Ad esempio, quando il sample-size te lo permette. Hai un numero talmente elevato di dati che la perdita di potenza risulta comunque accettabile.
Oppure quando il cutoff ha un razionale “solido” alle spalle ed è “globalmente condiviso”. Classico esempio: un Body Mass Index di 25, per separare i “normopeso” dai “sovrappeso”.
Infine, quando la variabile è distribuita in modo evidentemente “bimodale” e, dicotomizzando, viene pertanto rispettato il “razionale” della variabile (vedi il grafico qua sotto).

Per concludere, pensaci due volte prima di tagliare orrendamente una variabile in due metà. Potresti avere più danni che benefici. Esistono, spesso, tecniche statistiche che, quando opportunamente utilizzate, ti permettono di preservare la potenza dei tuoi test, per cui la qualità del tuo studio, mantenendo una chiara interpretabilità dei risultati.